Aditya Prakash
I'm a PhD Candidate in Computer Science at UIUC, advised by Saurabh Gupta & David Forsyth, working on 3D vision & robotics. My research is focused on modeling the interaction of different agents such as humans, robots & autonomous vehicles. During my PhD, I also spent time at the Microsoft Spatial AI Lab and NVIDIA Learning & Preception Research.
Prior to joining UIUC, I worked for 2 years with Andreas Geiger in the Autonomous Vision Group at the Max Planck Institute for Intelligent Systems & the University of Tübingen. Previously, I have also collaborated with researchers from NAVER, Indian Institute of Science, Adobe Research & Cornell Tech. I graduated from the IIT Roorkee in 2018 with the Department Gold Medal & the Institute Bronze Medal.
Email /
CV /
Google Scholar /
GitHub /
LinkedIn /
Twitter
|

|
|
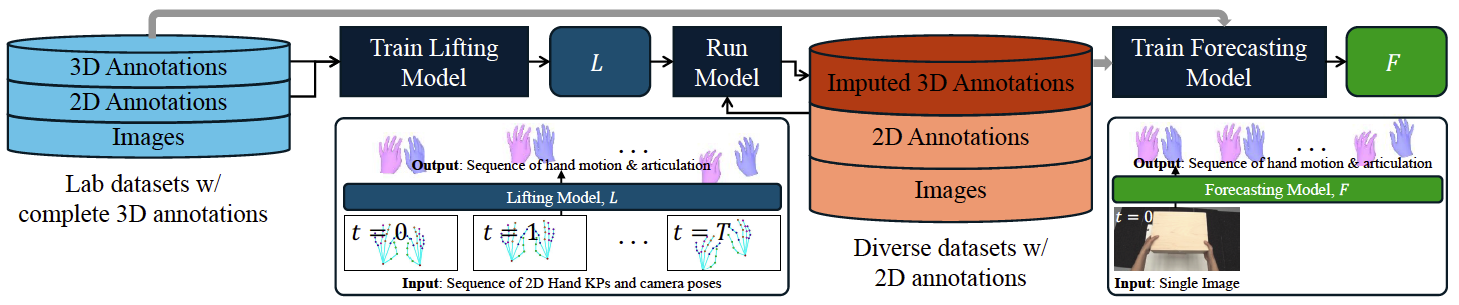
Bimanual 3D Hand Motion and Articulation Forecasting in Everyday Images
Aditya Prakash,
Richard Li,
David Forsyth,
Saurabh Gupta
ARXIV 2025
abstract /
bibtex /
project page /
code /
video
|
|
|
We tackle the problem of forecasting bimanual 3D hand motion & articulation from a single image in everyday settings. To address the lack of 3D hand annotations in diverse settings, we design an annotation pipeline consisting of a diffusion model to lift 2D hand keypoint sequences to 4D hand motion. For the forecasting model, we adopt a diffusion loss to account for the multimodality in hand motion distribution. Extensive experiments across 6 datasets show the benefits of training on diverse data with imputed labels (14% improvement) and effectiveness of our lifting (42% better) & forecasting (16.4% gain) models, over the best baselines, especially in zero-shot generalization to everyday images.
@article{Prakash2025Forehand4D,
author = {Prakash, Aditya and Forsyth, David and Gupta, Saurabh},
title = {Bimanual 3D Hand Motion and Articulation Forecasting in Everyday Images},
journal = {arXiv:2510.06145},
year = {2025}
}
|
|
How Do I Do That? Synthesizing 3D Hand Motion and Contacts for Everyday Interactions
Aditya Prakash,
Benjamin Lundell,
Dmitry Andreychuk,
David Forsyth,
Saurabh Gupta*,
Harpreet Sawhney*
Computer Vision and Pattern Recognition (CVPR) 2025 [Highlight]
abstract /
bibtex /
project page /
code /
video
|
|
|
We tackle the novel problem of predicting 3D hand motion and contact maps (or Interaction Trajectories) given a single RGB view, action text, and a 3D contact point on the object as input. Our approach consists of (1) Interaction Codebook: a VQVAE model to learn a latent codebook of hand poses and contact points, effectively tokenizing interaction trajectories, (2) Interaction Predictor: a transformer-decoder module to predict the interaction trajectory from test time inputs by using an indexer module to retrieve a latent affordance from the learned codebook. To train our model, we develop a data engine that extracts 3D hand poses and contact trajectories from the diverse HoloAssist dataset. We evaluate our model on a benchmark that is 2.5-10X larger than existing works, in terms of diversity of objects and interactions observed, and test for generalization of the model across object categories, action categories, tasks, and scenes. Experimental results show the effectiveness of our approach over transformer & diffusion baselines across all settings.
@inproceedings{Prakash2025LatentAct,
author = {Prakash, Aditya and Lundell, Benjamin and Andreychuk, Dmitry and Forsyth, David and Gupta, Saurabh and Sawhney, Harpreet},
title = {How Do I Do That? Synthesizing 3D Hand Motion and Contacts for Everyday Interactions},
booktitle = {Computer Vision and Pattern Recognition (CVPR)},
year = {2025}
}
|

|
3D Hand Pose Estimation in Everyday Egocentric Images
Aditya Prakash,
Ruisen Tu,
Matthew Chang,
Saurabh Gupta
European Conference on Computer Vision (ECCV) 2024
abstract /
bibtex /
project page /
code /
video /
poster
|
|
|
3D hand pose estimation in everyday egocentric images is
challenging for several reasons: poor visual signal (occlusion from the
object of interaction, low resolution & motion blur), large perspective
distortion (hands are close to the camera), and lack of 3D annotations
outside of controlled settings. While existing methods often use hand
crops as input to focus on fine-grained visual information to deal with
poor visual signal, the challenges arising from perspective distortion and
lack of 3D annotations in the wild have not been systematically studied.
We focus on this gap and explore the impact of different practices, i.e.
crops as input, incorporating camera information, auxiliary supervision,
scaling up datasets. We provide several insights that are applicable to
both convolutional and transformer models leading to better performance.
Based on our findings, we also present WildHands, a system for 3D hand
pose estimation in everyday egocentric images. Zero-shot evaluation on
4 diverse datasets (H2O, AssemblyHands, Epic-Kitchens, Ego-Exo4D)
demonstrate the effectiveness of our approach across 2D and 3D metrics,
where we beat past methods by 7.4% - 66%. In system level comparisons,
WildHands achieves the best 3D hand pose on ARCTIC egocentric split,
outperforms FrankMocap across all metrics and HaMeR on 3 out of 6
metrics while being 10x smaller and trained on 5x less data.
@inproceedings{Prakash2024Hands,
author = {Prakash, Aditya and Tu, Ruisen and Chang, Matthew and Gupta, Saurabh},
title = {3D Hand Pose Estimation in Everyday Egocentric Images},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024}
}
|
|
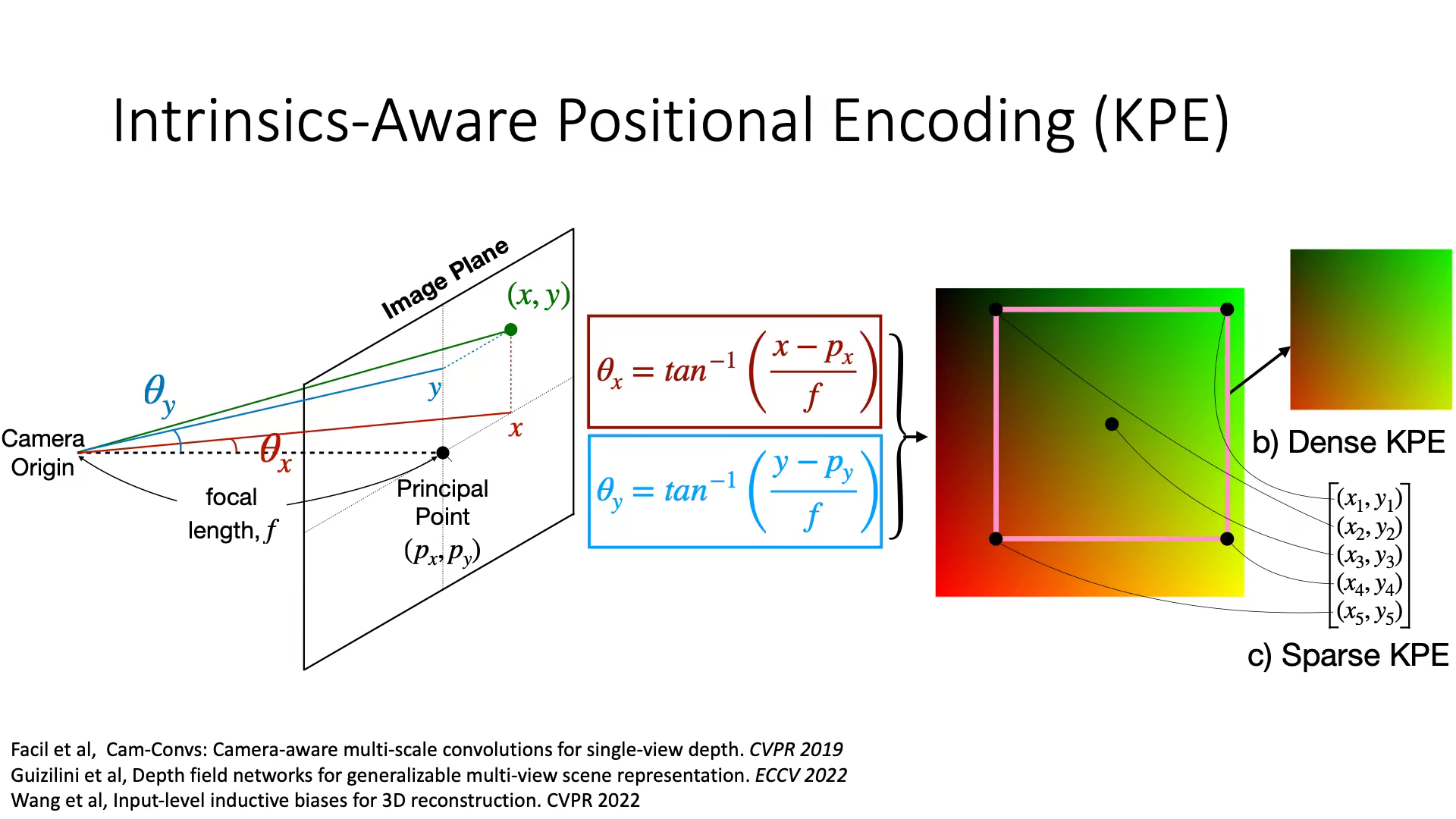
Mitigating Perspective Distortion-induced Shape Ambiguity in Image Crops
Aditya Prakash,
Arjun Gupta,
Saurabh Gupta
European Conference on Computer Vision (ECCV) 2024
abstract /
bibtex /
project page /
code /
video /
poster
|
|
|
Objects undergo varying amounts of perspective distortion as they move across a camera's field of view. Models for predicting 3D from a single image often work with crops around the object of interest and ignore the location of the object in the camera's field of view. We note that ignoring this location information further exaggerates the inherent ambiguity in making 3D inferences from 2D images and can prevent models from even fitting to the training data. To mitigate this ambiguity, we propose Intrinsics-Aware Positional Encoding (KPE), which incorporates information about the location of crops in the image and camera intrinsics. Experiments on three popular 3D-from-a-single-image benchmarks: depth prediction on NYU, 3D object detection on KITTI & nuScenes, and predicting 3D shapes of articulated objects on ARCTIC, show the benefits of KPE.
@inproceedings{Prakash2024Ambiguity,
author = {Prakash, Aditya and Gupta, Arjun, and Gupta, Saurabh},
title = {Mitigating Perspective Distortion-induced Shape Ambiguity in Image Crops},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024}
}
|
|
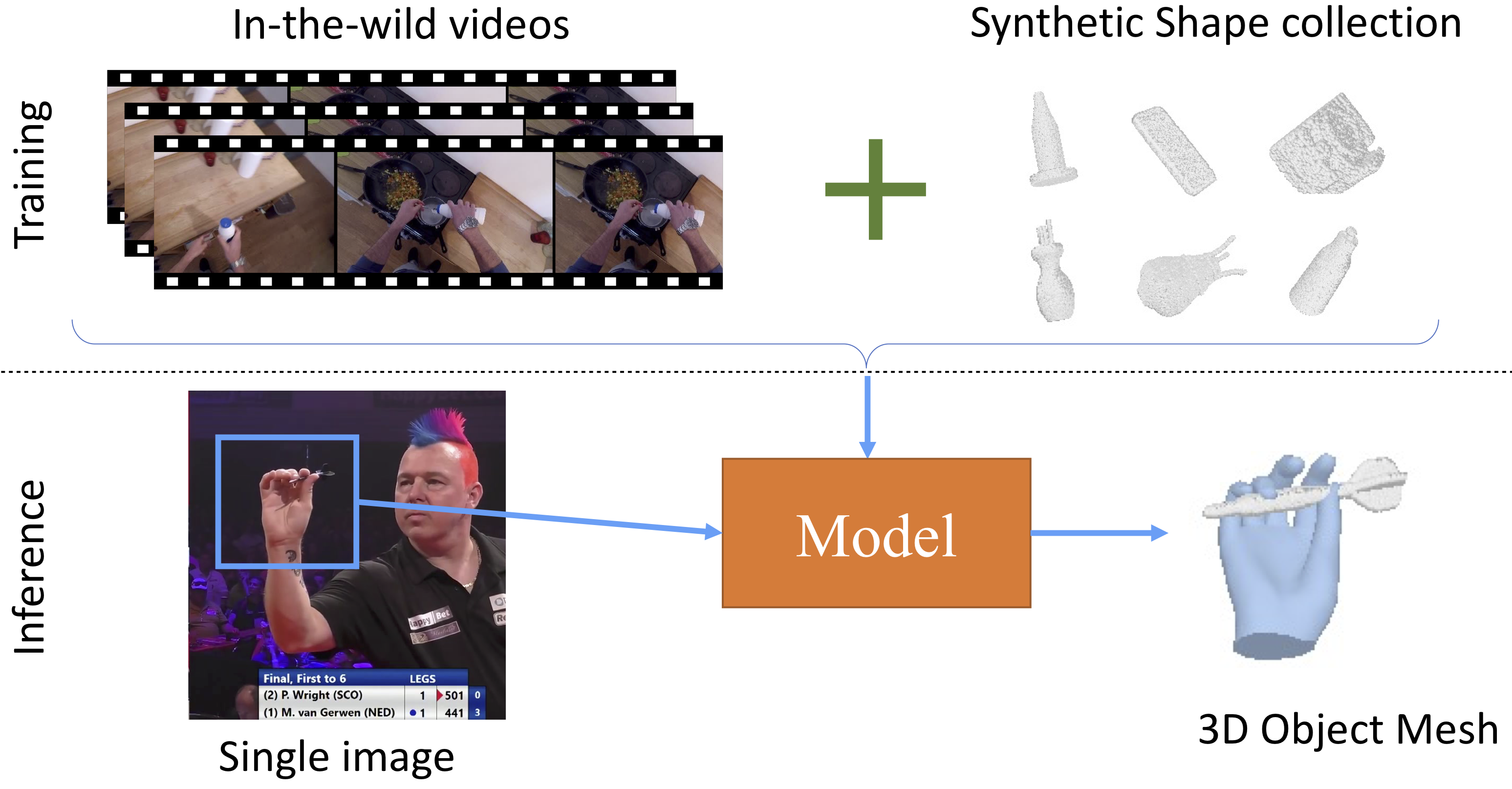
3D Reconstruction of Objects in Hands without Real World 3D Supervision
Aditya Prakash,
Matthew Chang,
Matthew Jin,
Ruisen Tu,
Saurabh Gupta
European Conference on Computer Vision (ECCV) 2024
abstract /
bibtex /
project page /
code /
video /
poster
|
|
|
Prior works for reconstructing hand-held objects from a single image train models on images paired with 3D shapes. Such data is challenging to gather in the real world at scale. Consequently, these approaches do not generalize well when presented with novel objects in in-the-wild settings. While 3D supervision is a major bottleneck, there is an abundance of a) in-the-wild raw video data showing hand-object interactions and b) synthetic 3D shape collections. In this paper, we propose modules to leverage 3D supervision from these sources to scale up the learning of models for reconstructing hand-held objects. Specifically, we extract multiview 2D mask supervision from videos and 3D shape priors from shape collections. We use these indirect 3D cues to train occupancy networks that predict the 3D shape of objects from a single RGB image. Our experiments in the challenging object generalization setting on in-the-wild MOW dataset show 11.6% relative improvement over models trained with 3D supervision on existing datasets.
@inproceedings{Prakash2024HOI,
author = {Prakash, Aditya and Chang, Matthew and Jin, Matthew and Tu, Ruisen and Gupta, Saurabh},
title = {3D Reconstruction of Objects in Hands without Real World 3D Supervision},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024}
}
|
|
Benchmarks and Challenges in Pose Estimation for Egocentric Hand Interactions with Objects
Zicong Fan*,
Takehiko Ohkawa*,
Linlin Yang*,
Nie Lin,
Zhishan Zhou,
Shihao Zhou,
Jiajun Liang,
Zhong Gao,
Xuanyang Zhang,
Xue Zhang,
Fei Li,
Zheng Liu,
Feng Lu,
Karim Abou Zeid,
Bastian Leibe,
Jeongwan On,
Seungryul Baek,
Aditya Prakash,
Saurabh Gupta
Kun He,
Yoichi Sato,
Otmar Hilliges,
Hyung Jin Chang,
Angela Yao
European Conference on Computer Vision (ECCV) 2024
abstract /
bibtex
|
|
|
We interact with the world with our hands and see it through
our own (egocentric) perspective. A holistic 3D understanding of such
interactions from egocentric views is important for tasks in robotics,
AR/VR, action recognition and motion generation. Accurately reconstructing such interactions in 3D is challenging due to heavy occlusion,
viewpoint bias, camera distortion, and motion blur from the head movement. To this end, we designed the HANDS23 challenge based on the
AssemblyHands and ARCTIC datasets with carefully designed training
and testing splits. Based on the results of the top submitted methods and
more recent baselines on the leaderboards, we perform a thorough analysis on 3D hand(-object) reconstruction tasks. Our analysis demonstrates
the effectiveness of addressing distortion specific to egocentric cameras,
adopting high-capacity transformers to learn complex hand-object interactions, and fusing predictions from different views. Our study further
reveals challenging scenarios intractable with state-of-the-art methods,
such as fast hand motion, object reconstruction from narrow egocentric
views, and close contact between two hands and objects. Our efforts will
enrich the community's knowledge foundation and facilitate future hand
studies on egocentric hand-object interactions.
@inproceedings{fan2024benchmarks,
title = {Benchmarks and Challenges in Pose Estimation for Egocentric Hand Interactions with Objects},
author = {Zicong Fan and Takehiko Ohkawa and Linlin Yang and Nie Lin and Zhishan Zhou and Shihao Zhou and Jiajun Liang and Zhong Gao and Xuanyang Zhang and Xue Zhang and Fei Li and Liu Zheng and Feng Lu and Karim Abou Zeid and Bastian Leibe and Jeongwan On and Seungryul Baek and Aditya Prakash and Saurabh Gupta and Kun He and Yoichi Sato and Otmar Hilliges and Hyung Jin Chang and Angela Yao},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024},
}
|
|
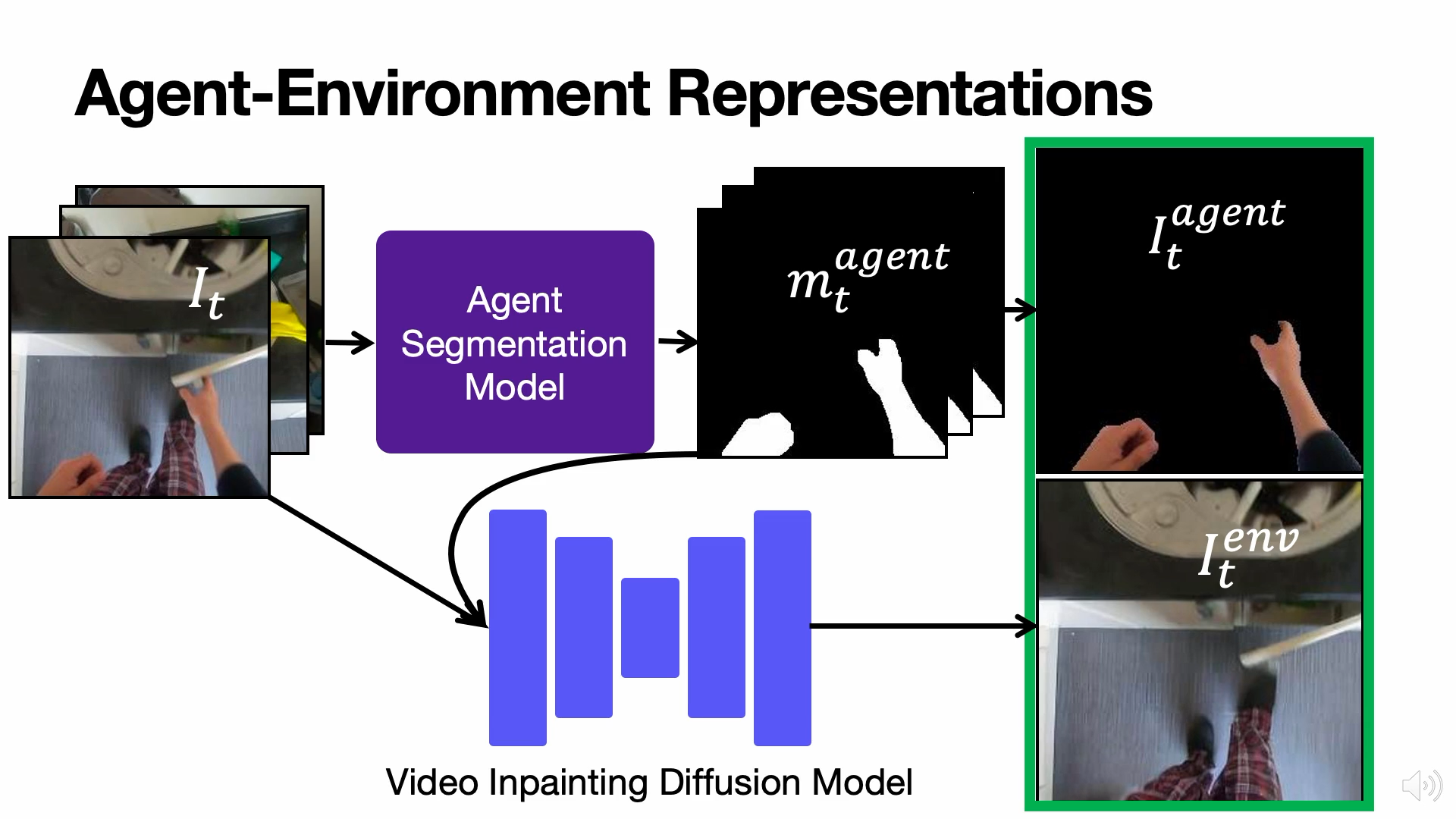
Look Ma, No Hands! Agent-Environment Factorization of Egocentric Videos
Matthew Chang,
Aditya Prakash,
Saurabh Gupta
Neural Information Processing Systems (NeurIPS) 2023
abstract /
bibtex /
project page /
code /
video
|
|
|
The analysis and use of egocentric videos for robotic tasks is made challenging by occlusion due to the hand and the visual mismatch between the human hand and a robot end-effector. In this sense, the human hand presents a nuisance. However, often hands also provide a valuable signal, e.g. the hand pose may suggest what kind of object is being held. In this work, we propose to extract a factored representation of the scene that separates the agent (human hand) and the environment. This alleviates both occlusion and mismatch while preserving the signal, thereby easing the design of models for downstream robotics tasks. At the heart of this factorization is our proposed Video Inpainting via Diffusion Model (VIDM) that leverages both a prior on real-world images (through a large-scale pre-trained diffusion model) and the appearance of the object in earlier frames of the video (through attention). Our experiments demonstrate the effectiveness of VIDM at improving inpainting quality on egocentric videos and the power of our factored representation for numerous tasks: object detection, 3D reconstruction of manipulated objects, and learning of reward functions, policies, and affordances from videos.
@inproceedings{Chang2023NEURIPS,
author = {Chang, Matthew and Prakash, Aditya and Gupta, Saurabh},
title = {Look Ma, No Hands! Agent-Environment Factorization of Egocentric Videos},
booktitle = {Neural Information Processing Systems (NeurIPS)},
year = {2023}
}
|
|
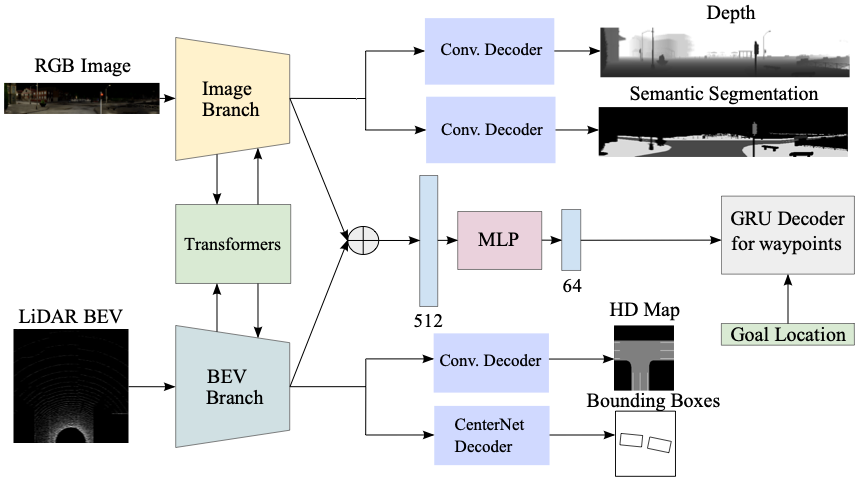
TransFuser: Imitation with Transformer-Based Sensor Fusion for Autonomous Driving
Kashyap Chitta,
Aditya Prakash,
Bernhard Jaeger,
Zehao Yu,
Katrin Renz,
Andreas Geiger
Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 2022
abstract /
bibtex /
code
|
|
|
How should we integrate representations from complementary sensors for autonomous driving? Geometry-based fusion has shown promise for perception (e.g. object detection, motion forecasting). However, in the context of end-to-end driving, we find that imitation learning based on existing sensor fusion methods underperforms in complex driving scenarios with a high density of dynamic agents. Therefore, we propose TransFuser, a mechanism to integrate image and LiDAR representations using self-attention. Our approach uses transformer modules at multiple resolutions to fuse perspective view and bird's eye view feature maps. We experimentally validate its efficacy on a challenging new benchmark with long routes and dense traffic, as well as the official leaderboard of the CARLA urban driving simulator. At the time of submission, TransFuser outperforms all prior work on the CARLA leaderboard in terms of driving score by a large margin. Compared to geometry-based fusion, TransFuser reduces the average collisions per kilometer by 48%.
@article{Chitta2022PAMI,
author = {Chitta, Kashyap and Prakash, Aditya and Jaeger, Bernhard and Yu, Zehao and Renz, Katrin and Geiger, Andreas},
title = {TransFuser: Imitation with Transformer-Based Sensor Fusion for Autonomous Driving},
journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year = {2022}
}
|
|
Multi-Modal Fusion Transformer for End-to-End Autonomous Driving
Aditya Prakash*,
Kashyap Chitta*,
Andreas Geiger
Computer Vision and Pattern Recognition (CVPR) 2021
abstract /
bibtex /
project page /
code /
video /
poster /
blog
|
|
|
How should representations from complementary sensors be integrated for autonomous driving? Geometry-based sensor fusion has shown great promise for perception tasks such as object detection and motion forecasting. However, for the actual driving task, the global context of the 3D scene is key, e.g. a change in traffic light state can affect the behavior of a vehicle geometrically distant from that traffic light. Geometry alone may therefore be insufficient for effectively fusing representations in end-to-end driving models. In this work, we demonstrate that imitation learning policies based on existing sensor fusion methods under-perform in the presence of a high density of dynamic agents and complex scenarios, which require global contextual reasoning, such as handling traffic oncoming from multiple directions at uncontrolled intersections. Therefore, we propose TransFuser, a novel Multi-Modal Fusion Transformer, to integrate image and LiDAR representations using attention. We experimentally validate the efficacy of our approach in urban settings involving complex scenarios using the CARLA urban driving simulator. Our approach achieves state-of-the-art driving performance while reducing collisions by 76% compared to geometry-based fusion.
@inproceedings{Prakash2021CVPR,
author = {Prakash, Aditya and Chitta, Kashyap and Geiger, Andreas},
title = {Multi-Modal Fusion Transformer for End-to-End Autonomous Driving},
booktitle = {Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}
|
|
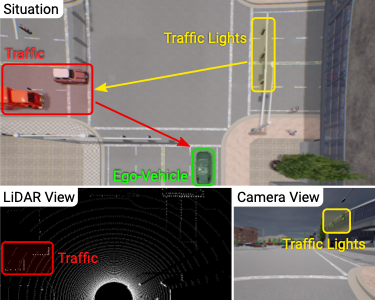
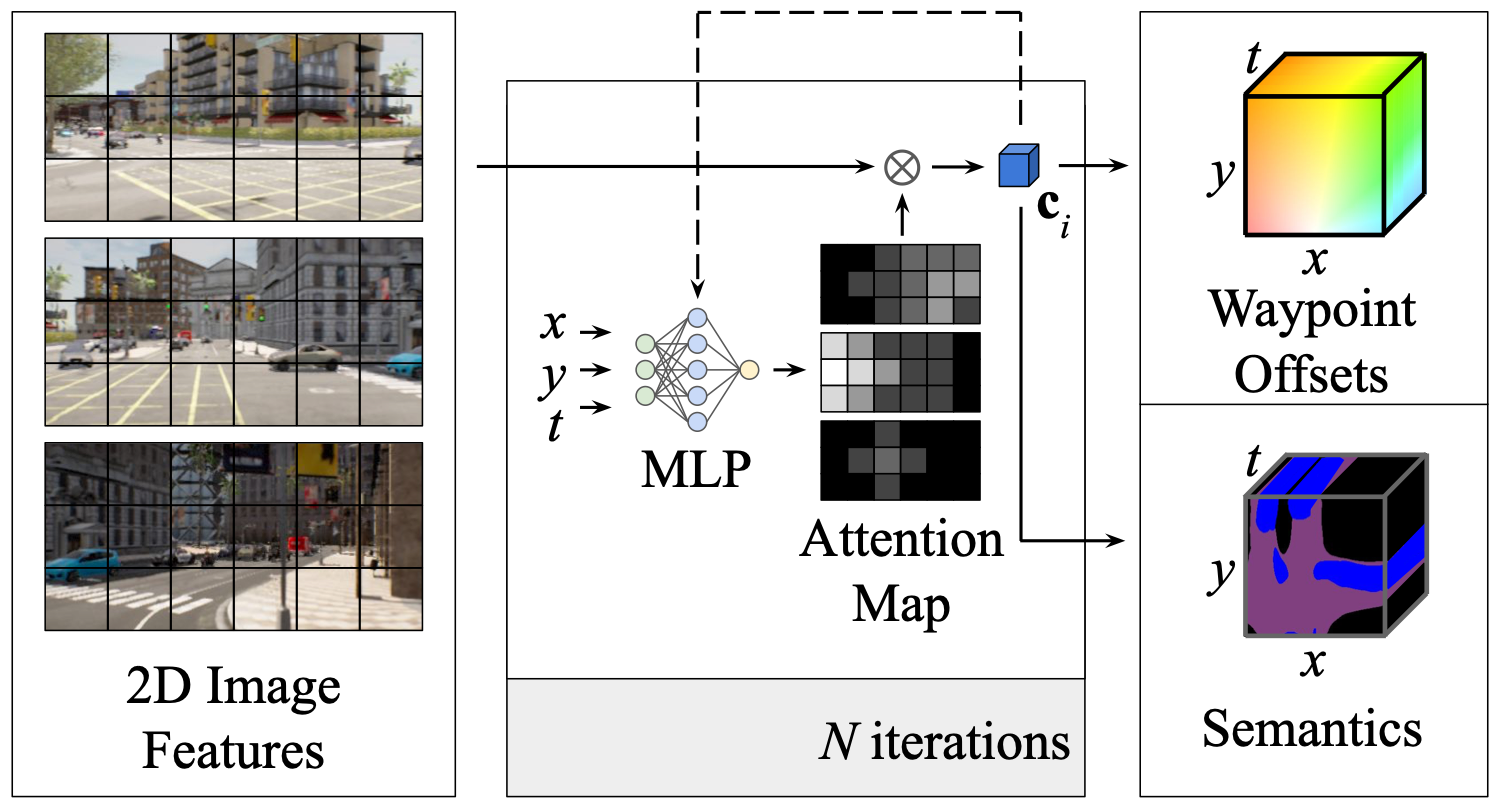
NEAT: Neural Attention Fields for End-to-End Autonomous Driving
Kashyap Chitta*,
Aditya Prakash*,
Andreas Geiger
International Conference on Computer Vision (ICCV) 2021
Transformers for Vision (T4V) Workshop at CVPR 2022 (Spotlight)
abstract /
bibtex /
code /
video
|
|
|
Efficient reasoning about the semantic, spatial, and temporal structure of a scene is a crucial pre-requisite for autonomous driving. We present NEural ATtention fields (NEAT), a novel representation that enables such reasoning for end-to-end Imitation Learning (IL) models. Our representation is a continuous function which maps locations in Bird's Eye View (BEV) scene coordinates to waypoints and semantics, using intermediate attention maps to iteratively compress high-dimensional 2D image features into a compact representation. This allows our model to selectively attend to relevant regions in the input while ignoring information irrelevant to the driving task, effectively associating the images with the BEV representation. NEAT nearly matches the state-of-the-art on the CARLA Leaderboard while being far less resource-intensive. Furthermore, visualizing the attention maps for models with NEAT intermediate representations provides improved interpretability. On a new evaluation setting involving adverse environmental conditions and challenging scenarios, NEAT outperforms several strong baselines and achieves driving scores on par with the privileged CARLA expert used to generate its training data.
@inproceedings{Chitta2021ICCV,
author = {Chitta, Kashyap and Prakash, Aditya and Geiger, Andreas},
title = {NEAT: Neural Attention Fields for End-to-End Autonomous Driving},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2021}
}
|
|
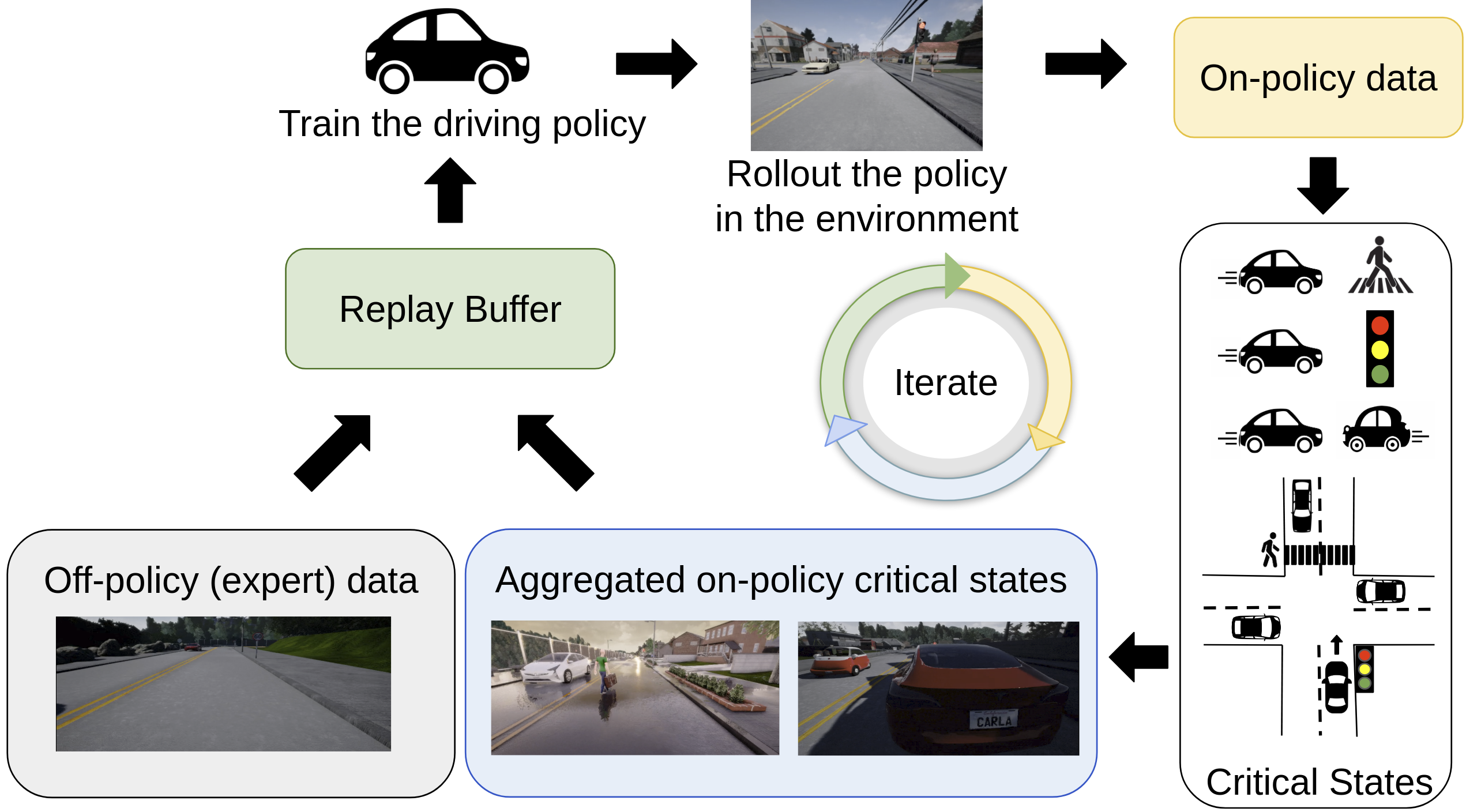
Exploring Data Aggregation in Policy Learning for Vision-based Urban Autonomous Driving
Aditya Prakash,
Aseem Behl,
Eshed Ohn-Bar,
Kashyap Chitta,
Andreas Geiger
Computer Vision and Pattern Recognition (CVPR) 2020
abstract /
bibtex /
project page /
code /
video
|
|
|
Data aggregation techniques can significantly improve vision-based policy learning within a training environment, e.g., learning to drive in a specific simulation condition. However, as on-policy data is sequentially sampled and added in an iterative manner, the policy can specialize and overfit to the training conditions. For real-world applications, it is useful for the learned policy to generalize to novel scenarios that differ from the training conditions. To improve policy learning while maintaining robustness when training end-to-end driving policies, we perform an extensive analysis of data aggregation techniques in the CARLA environment. We demonstrate how the majority of them have poor generalization performance, and develop a novel approach with empirically better generalization performance compared to existing techniques. Our two key ideas are (1) to sample critical states from the collected on-policy data based on the utility they provide to the learned policy in terms of driving behavior, and (2) to incorporate a replay buffer which progressively focuses on the high uncertainty regions of the policy’s state distribution. We evaluate the proposed approach on the CARLA NoCrash benchmark, focusing on the most challenging driving scenarios with dense pedestrian and vehicle traffic. Our approach improves driving success rate by 16% over stateof-the-art, achieving 87% of the expert performance while also reducing the collision rate by an order of magnitude without the use of any additional modality, auxiliary tasks, architectural modifications or reward from the environment.
@inproceedings{Prakash2020CVPR,
author = {Prakash, Aditya and Behl, Aseem and Ohn-Bar, Eshed and Chitta, Kashyap and Geiger, Andreas},
title = {Exploring Data Aggregation in Policy Learning for Vision-based Urban Autonomous Driving},
booktitle = {Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}
|
|
Learning Situational Driving
Eshed Ohn-Bar,
Aditya Prakash,
Aseem Behl,
Kashyap Chitta,
Andreas Geiger
Computer Vision and Pattern Recognition (CVPR) 2020
abstract /
bibtex /
project page /
video
|
|
|
Human drivers have a remarkable ability to drive in diverse visual conditions and situations, e.g., from maneuvering in rainy, limited visibility conditions with no lane markings to turning in a busy intersection while yielding to pedestrians. In contrast, we find that state-of-the-art sensorimotor driving models struggle when encountering diverse settings with varying relationships between observation and action. To generalize when making decisions across diverse conditions, humans leverage multiple types of situation-specific reasoning and learning strategies. Motivated by this observation, we develop a framework for learning a situational driving policy that effectively captures reasoning under varying types of scenarios. Our key idea is to learn a mixture model with a set of policies that can capture multiple driving modes. We first optimize the mixture model through behavior cloning, and show it to result in significant gains in terms of driving performance in diverse conditions. We then refine the model by directly optimizing for the driving task itself, i.e., supervised with the navigation task reward. Our method is more scalable than methods assuming access to privileged information, e.g., perception labels, as it only assumes demonstration and reward-based supervision. We achieve over 98% success rate on the CARLA driving benchmark as well as state-of-the-art performance on a newly introduced generalization benchmark.
@inproceedings{Ohn-Bar2020CVPR,
author = {Ohn-Bar, Eshed and Prakash, Aditya and Behl, Aseem and Chitta, Kashyap and Geiger, Andreas},
title = {Learning Situational Driving},
booktitle = {Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}
|

|
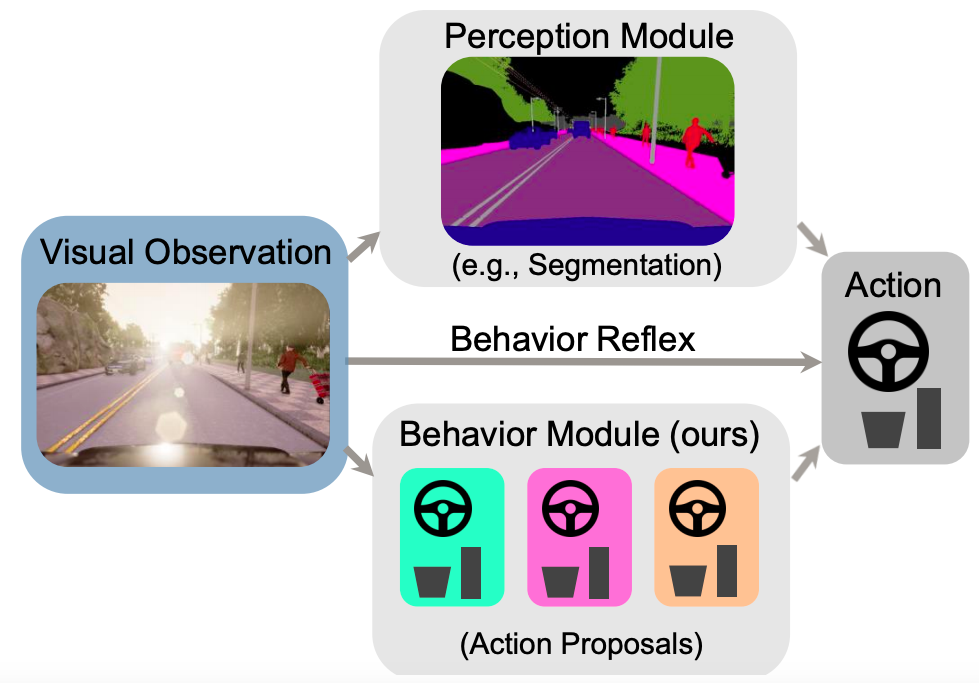
Label Efficient Visual Abstractions for Autonomous Driving
Aseem Behl*,
Kashyap Chitta*,
Aditya Prakash,
Eshed Ohn-Bar,
Andreas Geiger
International Conference on Intelligent Robots and Systems (IROS) 2020
abstract /
bibtex /
arxiv
|
|
|
It is well known that semantic segmentation can be used as an effective intermediate representation for learning driving policies. However, the task of street scene semantic segmentation requires expensive annotations. Furthermore, segmentation algorithms are often trained irrespective of the actual driving task, using auxiliary image-space loss functions which are not guaranteed to maximize driving metrics such as safety or distance traveled per intervention. In this work, we seek to quantify the impact of reducing segmentation annotation costs on learned behavior cloning agents. We analyze several segmentation-based intermediate representations. We use these visual abstractions to systematically study the trade-off between annotation efficiency and driving performance, i.e., the types of classes labeled, the number of image samples used to learn the visual abstraction model, and their granularity (e.g., object masks vs. 2D bounding boxes). Our analysis uncovers several practical insights into how segmentation-based visual abstractions can be exploited in a more label efficient manner. Surprisingly, we find that state-of-the-art driving performance can be achieved with orders of magnitude reduction in annotation cost. Beyond label efficiency, we find several additional training benefits when leveraging visual abstractions, such as a significant reduction in the variance of the learned policy when compared to state-of-the-art end-to-end driving models.
@inproceedings{Behl2020IROS,
author = {Behl, Aseem and Chitta, Kashyap and Prakash, Aditya and Ohn-Bar, Eshed and Geiger, Andreas},
title = {Label Efficient Visual Abstractions for Autonomous Driving},
booktitle = {International Conference on Intelligent Robots and Systems (IROS)},
year = {2020}
}
|
|
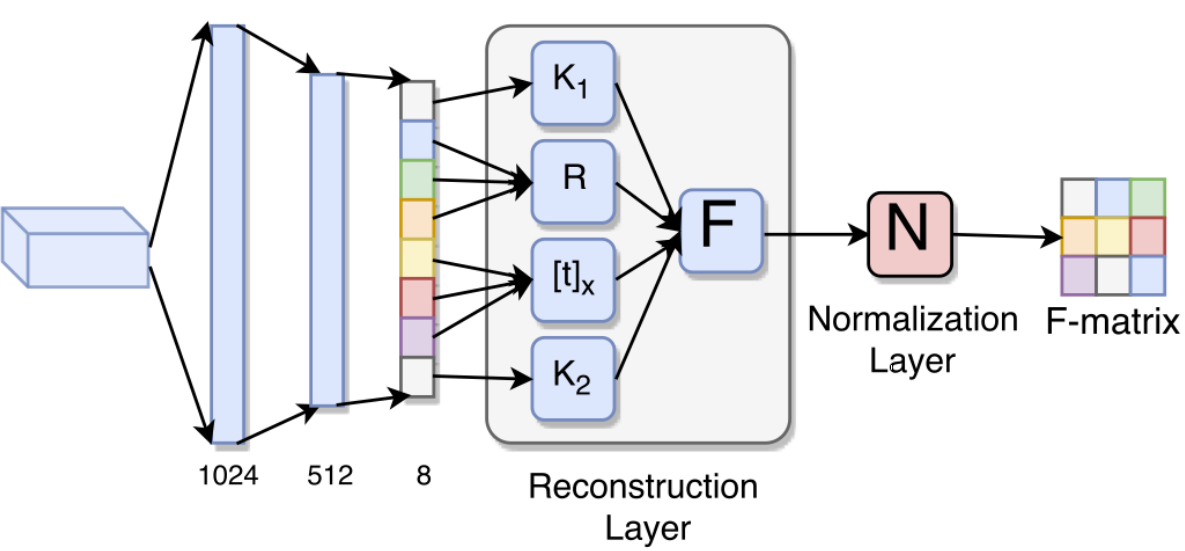
Deep Fundamental Matrix Estimation without Correspondences
Omid Poursaeed*,
Guandao Yang*,
Aditya Prakash*,
Qiuren Fang,
Hanqing Jiang,
Bharath Hariharan,
Serge Belongie
European Conference on Computer Vision (ECCV) Workshops 2018
abstract /
bibtex /
arxiv /
code
|
|
|
Estimating fundamental matrices is a classic problem in computer vision. Traditional methods rely heavily on the correctness of estimated key-point correspondences, which can be noisy and unreliable. As a result, it is difficult for these methods to handle image pairs with large occlusion or significantly different camera poses. In this paper, we propose novel neural network architectures to estimate fundamental matrices in an end-to-end manner without relying on point correspondences. New modules and layers are introduced in order to preserve mathematical properties of the fundamental matrix as a homogeneous rank-2 matrix with seven degrees of freedom. We analyze performance of the proposed model on the KITTI dataset, and show that they achieve competitive performance with traditional methods without the need for extracting correspondences.
@inproceedings{Poursaeed2018ECCVW,
author = {Poursaeed, Omid and Yang, Guandao and Prakash, Aditya and Fang, Qiuren and Jiang, Hanqing and Hariharan, Bharath and Belongie, Serge},
title = {Deep Fundamental Matrix Estimation without Correspondences},
booktitle = {European Conference on Computer Vision (ECCV) Workshops},
year = {2018}
}
|
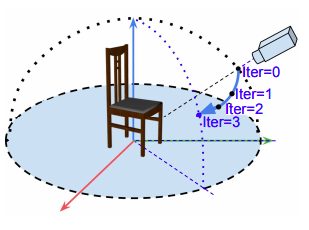
|
iSPA-Net: Iterative Semantic Pose Alignment Network
Jogendra Nath Kundu*,
Aditya Ganeshan*,
Rahul M Venkatesh*,
Aditya Prakash,
R. Venkatesh Babu
ACM Conference on Multimedia (ACM MM) 2018
abstract /
bibtex /
arxiv /
code
|
|
|
Understanding and extracting 3D information of objects from monocular 2D images is a fundamental problem in computer vision. In the task of 3D object pose estimation, recent data driven deep neural network based approaches suffer from scarcity of real images with 3D keypoint and pose annotations. Drawing inspiration from human cognition, where the annotators use a 3D CAD model as structural reference to acquire ground-truth viewpoints for real images; we propose an iterative Semantic Pose Alignment Network, called iSPA-Net. Our approach focuses on exploiting semantic 3D structural regularity to solve the task of fine-grained pose estimation by predicting viewpoint difference between a given pair of images. Such image comparison based approach also alleviates the problem of data scarcity and hence enhances scalability of the proposed approach for novel object categories with minimal annotation. The fine-grained object pose estimator is also aided by correspondence of learned spatial descriptor of the input image pair. The proposed pose alignment framework enjoys the faculty to refine its initial pose estimation in consecutive iterations by utilizing an online rendering setup along with effectiveness of a non-uniform bin classification of pose-difference. This enables iSPA-Net to achieve state-of-the-art performance on various real image viewpoint estimation datasets. Further, we demonstrate effectiveness of the approach for multiple applications. First, we show results for active object viewpoint localization to capture images from similar pose considering only a single image as pose reference. Second, we demonstrate the ability of the learned semantic correspondence to perform unsupervised part-segmentation transfer using only a single part-annotated 3D template model per object class. To encourage reproducible research, we have released the codes for our proposed algorithm.
@inproceedings{Kundu2018ACMMM,
author = {Kundu, Jogendra Nath and Ganeshan, Aditya and Venkatesh, Rahul M. and Prakash, Aditya and Babu, R. Venkatesh},
title = {iSPA-Net: Iterative Semantic Pose Alignment Network},
booktitle = {ACM Conference on Multimedia (ACM MM)},
year = {2018}
}
|
|